An investigation of the predictors of thyroid cancer in patients with thyroid nodules
Authors
Affiliations
Ovie Edafe
Department of Oncology & Metabolism, University of Sheffield
Neil Shephard
Research Software Engineer, Department of Computer Science, University of Sheffield
Karen Sisley
Senior Lecturer, Clinical Medicine, School of Medicine and Population Health, University of Sheffield
Sabapathy P Balasubramanian
Directorate of General Surgery, Sheffield Teaching Hospitals NHS Foundation Trust
Published
April 26, 2024
Abstract
An abstract summarising the work undertaken and the overall conclusions can be placed here. Sub-headings are currently removed because they conflict with those in the body of the text and mess up the links in the Table of Contents.
Keywords
Thyroid nodules, Thyroid cancer
In [1]:
## Libraries for data manipulation, plotting and tabulating (sorted alphabetically)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ kernlab::alpha() masks scales::alpha(), ggplot2::alpha()
✖ scales::col_factor() masks readr::col_factor()
✖ purrr::cross() masks kernlab::cross()
✖ purrr::discard() masks scales::discard()
✖ mice::filter() masks dplyr::filter(), stats::filter()
✖ stringr::fixed() masks recipes::fixed()
✖ dplyr::lag() masks stats::lag()
✖ yardstick::spec() masks readr::spec()
✖ Hmisc::src() masks dplyr::src()
✖ Hmisc::summarize() masks dplyr::summarize()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(vip)
Attaching package: 'vip'
The following object is masked from 'package:utils':
vi
## Set global optionsoptions(digits =3)train <-0.75test <-0.25## Set directories based on current locationbase_dir <-getwd()data_dir <-paste(base_dir, "data", sep ="/")csv_dir <-paste(data_dir, "csv", sep ="/")r_dir <-paste(data_dir, "r", sep ="/")r_scripts <-paste(base_dir, "r", sep ="/")## Load data#### The following line runs the `r/shf_thy_nod.R` script which reads the data from CSV and cleans/tidies it.## If something has changed in that file or the underlying data (in `data/csv/sheffield_thyroid_module.R`) then this## line should be uncommented and the code will run. At the end of the file it saves the data to `data/r/clean.rds`.source("r/shf_thy_nod.R")
Rows: 1364 Columns: 33
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (26): gender, ethnicity, eligibility, incidental_nodule, palpable_nodule...
dbl (7): study_id, age_at_scan, albumin, tsh_value, lymphocytes, monocyte, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
## If nothing has changed in the underlying data or the cleaning/tidying process then the last version of the data,## saved to `data/r/clean.rds` can be loaded by commenting out the line above and uncommenting the line below.#df <- readRDS(paste(r_dir, "clean.rds", sep="/"))## @ns-rse 2024-06-18:## We want this table to match the model, therefore rather than repeat ourselves we move the subsetting to give us## df_complete to here and assign to df_complete. This is then passed into gtsummary::tbl_summary() and is available for## the next code chunk.#### This is the point at which you should subset your data for those who have data available for the variables of## interest. The variables here should include the outcome `final_pathology` and the predictor variables that are set in## the code chunk `recipe`. May want to move this to another earlier in the processing so that the number of rows can be## counted and reported.df_complete <- df |> dplyr::select( age_at_scan, gender, ethnicity, incidental_nodule, palpable_nodule, rapid_enlargement, compressive_symptoms, hypertension, vocal_cord_paresis, graves_disease, hashimotos_thyroiditis, family_history_thyroid_cancer, exposure_radiation, albumin, tsh_value, lymphocytes, monocyte, bta_u_classification, solitary_nodule, size_nodule_mm, cervical_lymphadenopathy, thy_classification, final_pathology) |>## @ns-rse 2024-06-14 :## I would consider removing this dplyr::filter() and instead using the recipes::step_filter_missing() as is now in## place below## dplyr::filter(if_any(everything(), is.na))## Instead I think it might be useful to remove individuals who do not have a value for final_pathology here dplyr::filter(!is.na(final_pathology))
1 Introduction
Thyroid nodules are common. The challenge in the management of thyroid nodules is differentiating between benign and malignant nodule thyroid nodules.The use fine needle aspiration and cytology (FNAC) still leaves around 20% of patients that cannot be clearly classified as either benign or malignant. This scenario traditionally leads to diagnostic hemithyroidectomy for definitive histology. Other clinical variables such as patients’ demographics, clinical and biochemical factors have been shown to be associated with thyroid cancer in patients with thyroid nodules. This has been utilised in studies evaluating predictors of thyroid cancer with a view of creating a model to aid prediction. Standard practice on the management of thyroid nodules does not utilise these non ultrasound and non cytological factors. Combination of these variables considered to be significant with ultrasound and cytological characteristics may improve management of patients with thyroid nodules. Thyroid nodules are increasingly being incidentally detected with increased use of imaging in the evaluation of non thyroid related pathologies. Thus, leading to increase investigation of thyroid nodules and subsequent increased number of thyroid operations in non diagnostic cases. There are morbidities associated with thyroid surgery including scar, recurrent laryngeal nerve injury, hypothyroidism and hypoparathyroidism. We performed a systematic review to evaluate for predictors of thyroid cancer specifically in patients presenting with thyroid nodules. The systematic review a number of potential important variables that may be useful in the prediction of thyroid cancer in patients with thyroid nodules. The aim of this study was to evaluate the predictors of thyroid cancer with a view of improving prediction of thyroid cancer using computer age statistical inference techniques (Efron and Hastie (2016)).
2 Methods
This study was reported as per the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines
2.1 Study design
This was a retrospective cohort study.
2.2 Setting
The study was conducted at the Sheffield Teaching hospitals NHS Foundation Trusts. This is a tertiary referral centre for the management of thyroid cancer
2.3 Participants
We included all consecutive patients who presented with thyroid nodule(s) or that were found to have thyroid nodule(s) on ultrasound done for thyroid pathology or for other non thyroid related pathologies
2.4 Variables
Variable evaluated was based on findings from a systematic review evaluating predictors of thyroid cancer in patients with thyroid nodules. Data on the following variables were collected: patient demographics (age, gender, ethnicity), nodule presentation (incidental nodule, palpable nodule, rapid enlargement, compressive symptoms, vocal paresis), past medical history (hypertension, Graves’ disease, Hashimotos’ thyroiditis, family history of thyroid cancer, exposure to neck radiation), biochemistry (thyroid stimulating hormone, lymphocytes, monocytes), ultrasound characteristics (British Thyroid Association ultrasound (BTA U), nodule size, solitary nodule, nodule consistency, cervical lymphadenopathy), Royal College of Pathology (RCP) FNAC classification, type of thyroid surgery, and histological diagnosis.
2.5 Data source
Data was collected from patients’ case notes and electronic patients’ database using a standardised data collection proforma. This was initially piloted on 30 patients and revised to improve data entry. In addition a number of variables that were not standard collected during workout of patients were not further checked; these include body mass index (BMI), serum thyroglobulin, serum triiodothyronine (T3), thyroxine (T4), thyroglobulin antibody (TgAb), thyroid peroxidase antibody (TP0Ab), and urinary iodine.
2.6 Study size
We sought to have a large data set of at least 100 thyroid nodules with a cancer diagnosis using consecutive sampling technique. We aimed for a total of 1500 patients with thyroid nodules to achieve our target sample size. With the use of modern statistical techniques, we proposed such number will be appropriate to detect important variables if it exists.
2.7 Data analysis
Data was cleaned and analysed using the R Statistical Software R Core Team (2023) and the Tidyverse (Wickham et al. (2019)), Tidymodels (Kuhn and Wickham (2020)) collection of packages.
2.8 Imputation
The dataset is incomplete and there are missing observations across all variables to varying degrees. In order to maximise the sample available for analysis imputation was used to infer missing values. The Multivariat Imputation via Chained Equations (MICE and implemented in the eponymous R package Buuren and Groothuis-Oudshoorn (2011)) was employed which assumes data is missing at random (a difficult assumption to formally test). The approach takes each variable with missing data and attempts to predict it using statistical modelling based on the observed values. In essence it is the same approach as the statistical methods being employed to try and predict Thyroid Cancer and there are a range of statistical techniques available which include
2.9 Modelling
We used a selection of statistic modelling techniques to evaluate association between variables and thyroid cancer in patients with thyroid nodules. The patient population was split into training and testing cohorts in a ratio of 0.75:0.25 and each model is fitted using the training cohort. This split ratio is generally used in traditional machine learning techniques. The training set of the data was used to estimate the relation between variables and thyroid cancer. The larger the training data, the better it is for the model to learn the trends. The test set was used to determine the accuracy of the model in predicting thyroid cancer; the bigger the test data the more confidence we have in the model prognostic values. We used simple randomisation technique for the split to prevent bias in the data split. We ensured that there was no duplicate in the data sets so any test data was not accidentally trained. Furthermore, cross validation was used to estimate the accuracy of the various machine learning models. The k-fold techniques splits the data in ?10 folds, and the data was trained on all but one of the the fold, and the one fold not trained is used to test the data. This was repeated multiple times using a different fold for test and the others for training until all the folds is utilised for training and testing. Following multiple training process with k-fold, we selected the model that has the best predictive value for thyroid cancer in the test cohort. We also used the leave one out (loo) cross-validation to train and test the data set.In this technique, all but one observation is use to train the data set and one observation is use to test the data; this is repeated until all the data test is used for testing and training. The model with the best predictive value was selected.
2.9.1 LASSO / Elastic Net
LASSO (Least Absolute Shrinkage and Selection Operatror) and Elastic Net Zou and Hastie (2005) are regression methods that perform variable selection. The original LASSO method proposed by “Regression Shrinkage and Selection via the Lasso” (1996) allows the coefficients for independent/predictor variables to “shrink” down towards zero, effectively eliminating them from influencing the model, this is often referred to as L1 regularisation. The Elastic Net Zou and Hastie (2005) improves on the LASSO by balancing L1 regularisation with ridge-regression or L2 regularisation which helps avoid over-fitting.
Both methods avoid many of the shortcomings/pitfalls of stepwise variable selection Thompson (1995)Smith (2018) and have been shown to be more accurate in clinical decision making in small datasets with well code, externally selected variables Steyerberg et al. (2001)
2.9.2 Random Forest
To add reference The random forest plot is an extension of the decision tree methodology to reduce variance. Decision trees are very sensitive to the training data set and can lead to high variance; thus potential issues with generalisation of the model. The random forest plot selects random observation of the dataset to create multiple decision trees. Random variables are selected for each tree in the training of the data set. The aggregated output of the generated decision trees is then used to create an estimate.
2.9.3 Gradient Boosting
Gradient boosting is a machine learning algorithm that uses decision tree as a base model. The data is initially trained on this decision tree, but the initial prediction is weak, thus termed a weak based model. In gradient boosting the process is iterative; a sequence of decision trees is added to the initial tree. Each tree learns from the prior tree(s) to improve the model, increasing strength and minimising error.
2.9.4 SVM
Support Vector Machines is an approach that allows observation with a binary classifications to be separated using a hyperplane. It finds a hyperplane that best stratify the two classes i.e benign versus malignant nodules. SVM finds the hyperplane with the maximum margin of separation between the two classes. The support vectors are the data point that are positioned close to the margin of the hyperplane and these used to select the most appropraite hyperplane. The support vectors are the only data points that have an influence on the maximum margin in SVM.
?@tbl-patient-demographics shows the demographics of patients included in this study. A total of 1364 patients were included in this study with a median (IQR) age of 55 ( 41-69). ?@tbl-clinical-characteristics shows the distribution of clinical variables evaluated between benign and malignant thyroid nodules.
3.1 Data Description
A summary of the variables that are available in this data set can be found in Table 3.
The completeness of the original data is shown in tables ?@tbl-imputation-summary-pmm, ?@tbl-imputation-summary-cart, ?@tbl-imputation-summary-rf, along with summaries from four rounds of imputation for each of three imputation methods. Where variables continuous (e.g. age or size_nodule_mm) basic summary statistics in the form of mean, standard deviation, median and inter-quartile range are given. For categorical variables that are logical TRUE/FALSE (e.g. palpable_nodule) the number of TRUE observations and the percentage (of those with observed data for that variable) are shown along with the number that are Unknown. For categorical variables such as gender percentages in each category are reported. For all variables an indication of the number of missing observations is also given and it is worth noting that there are 214 instances where the final_pathology is not known which reduces the sample size to 1150.
3.1.1 Missing Data
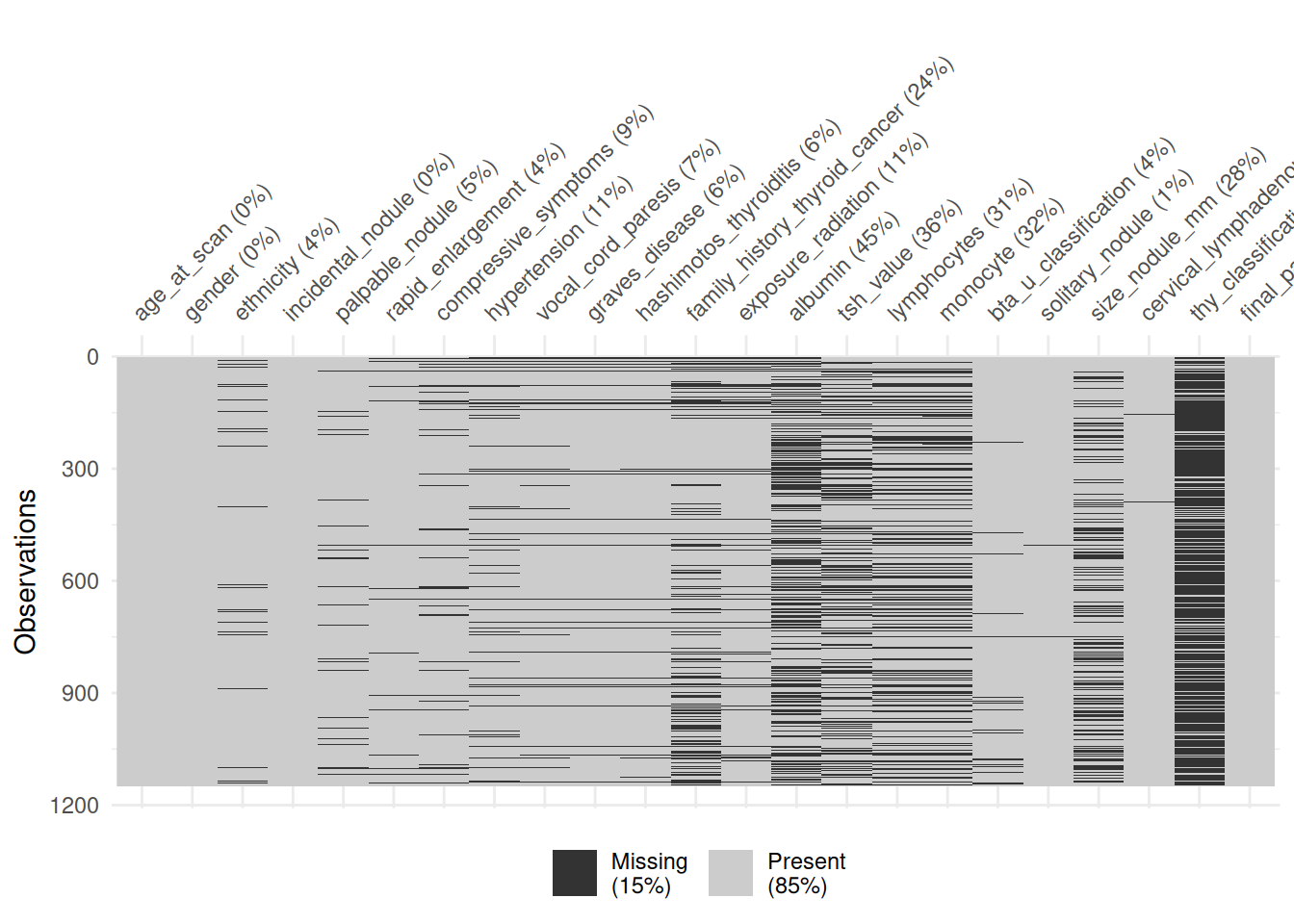
More detailed tabulations of missing data by variable are shown in Table 1 which shows the number and percentage of missing data for each variable and by case in Table 2 which shows how much missing data each case has. A visualisation of this is shown in Figure 1 .
NB - Currently there is a bug in the stable release of Quarto which prevents rendering of the missing data figures. It is fixed in development version v1.6.1 (currently available as pre-release, so if things don’t render try upgrading).
naniar::miss_var_summary(df_complete) |> knitr::kable(col.names=c("Variable", "N", "%"),caption="Summary of missing data by variable.")
Table 1: Summary of missing data by variable.
Variable
N
%
thy_classification
915
79.6
albumin
515
44.8
tsh_value
413
35.9
monocyte
363
31.6
lymphocytes
359
31.2
size_nodule_mm
319
27.7
family_history_thyroid_cancer
281
24.4
hypertension
126
11.0
exposure_radiation
121
10.5
compressive_symptoms
106
9.22
vocal_cord_paresis
76
6.61
hashimotos_thyroiditis
73
6.35
graves_disease
67
5.83
palpable_nodule
58
5.04
bta_u_classification
50
4.35
ethnicity
48
4.17
rapid_enlargement
43
3.74
cervical_lymphadenopathy
9
0.783
solitary_nodule
8
0.696
incidental_nodule
5
0.435
age_at_scan
0
0
gender
0
0
final_pathology
0
0
In [5]:
In [6]:
naniar::miss_case_table(df_complete) |> knitr::kable(col.names=c("Missing Variables", "N", "%"),caption="Summary of missing data by case, how much missing data is there per person?")
Table 2: Summary of missing data by case, how much missing data is there per person?
Missing Variables
N
%
0
65
5.652
1
227
19.739
2
229
19.913
3
181
15.739
4
139
12.087
5
102
8.870
6
76
6.609
7
35
3.043
8
30
2.609
9
13
1.130
10
19
1.652
11
15
1.304
12
9
0.783
13
4
0.348
14
3
0.261
15
2
0.174
16
1
0.087
In [7]:
visdat::vis_miss(df_complete)
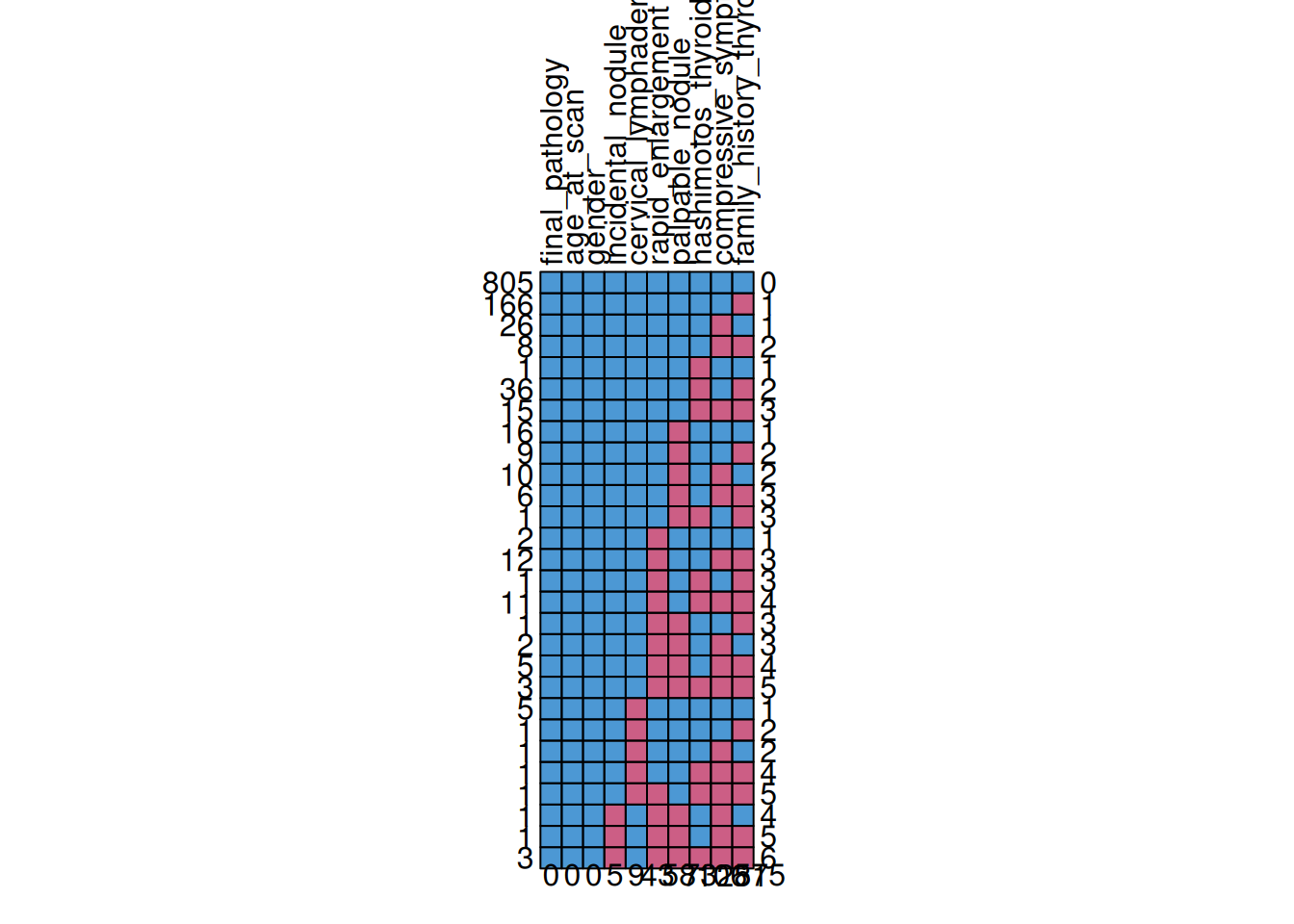
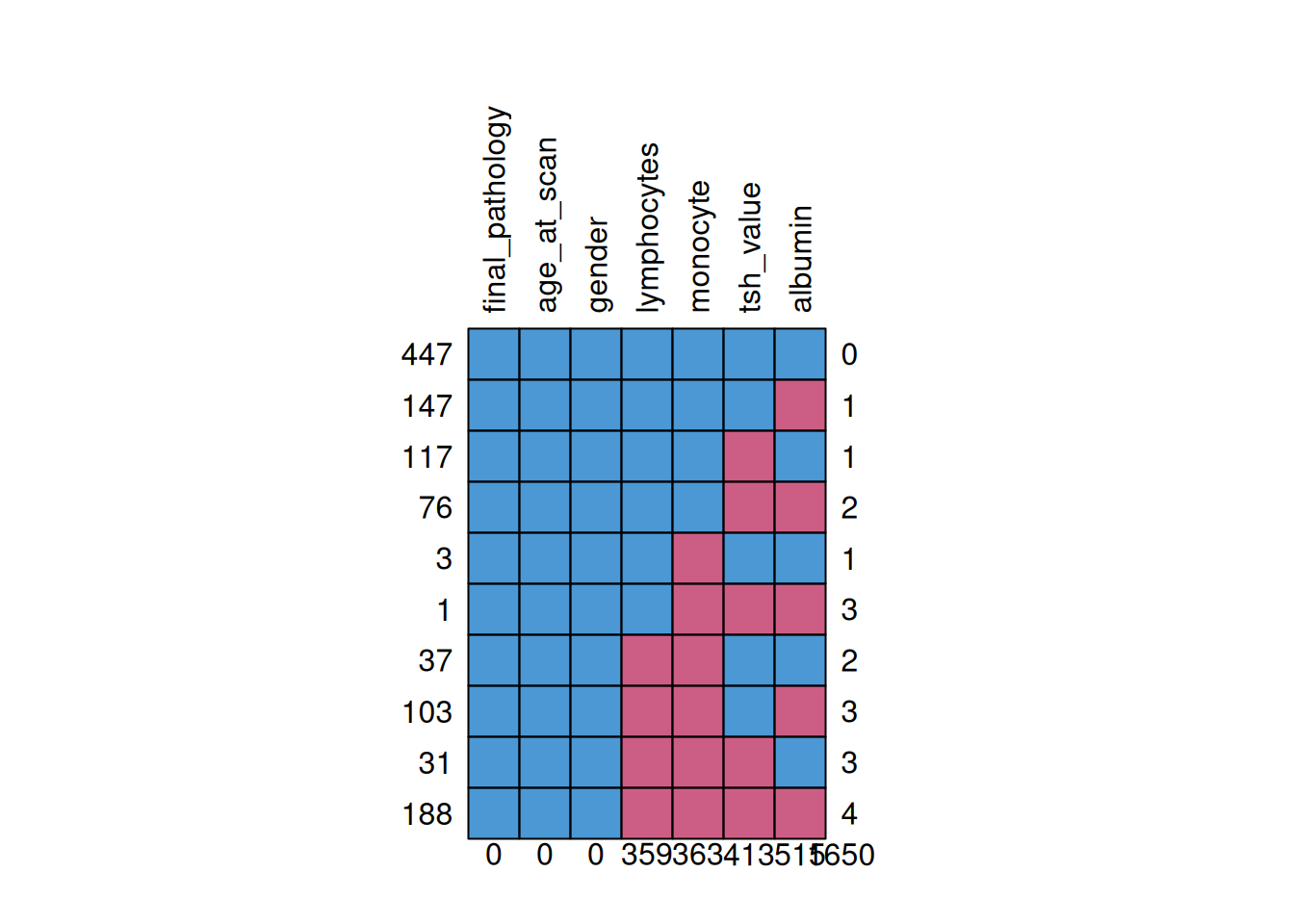
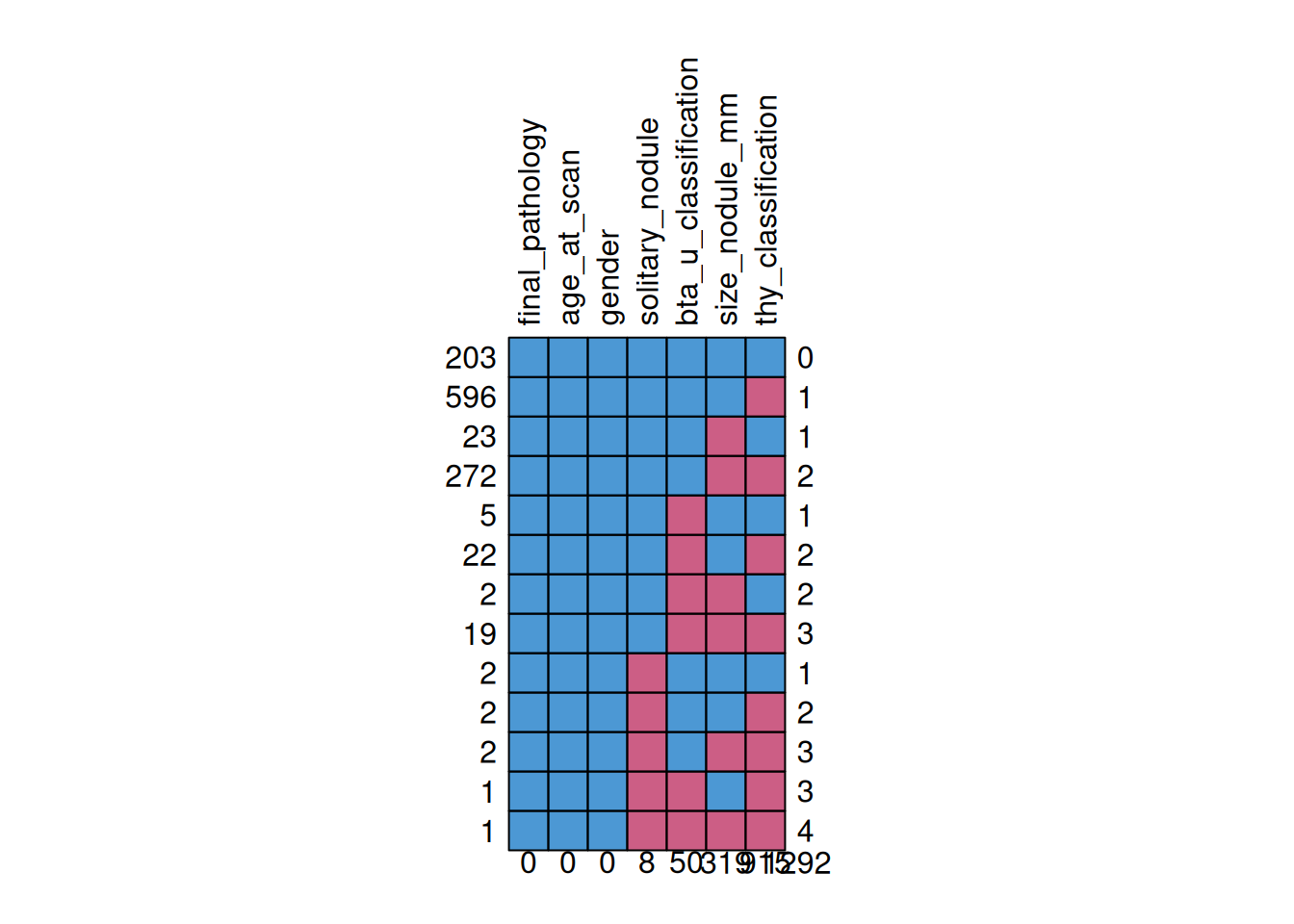
The MICE package also provides tools for visualising missing data and these are shown in figures Figure 2, ?@fig-mice-vis-missing-biomarker and Figure 4.
The columns of these plots, labelled along the top, show the variable, if a cell is blue it indicates data is present, if it is red it indicates there is missing data. The left-hand side shows the total number of observations for that rows particular combination of variables with number of missing variables indicated on the right. The first row shows that for these variables there are 604 observations with zero missing data across the listed variables, the second row indicates there are 166 observations with justfamily_history_thyroid_cancer but there are some with this missing and other variables. The numbers on the bottom of the figure indicate the total number of missing observations for that variable (e.g. for family_history_thyroid_cancer there is a total of 281 missing observations).
TODO - Workout why out-width: "80%" isn’t applied to these figures and/or how to make the All figure readable.
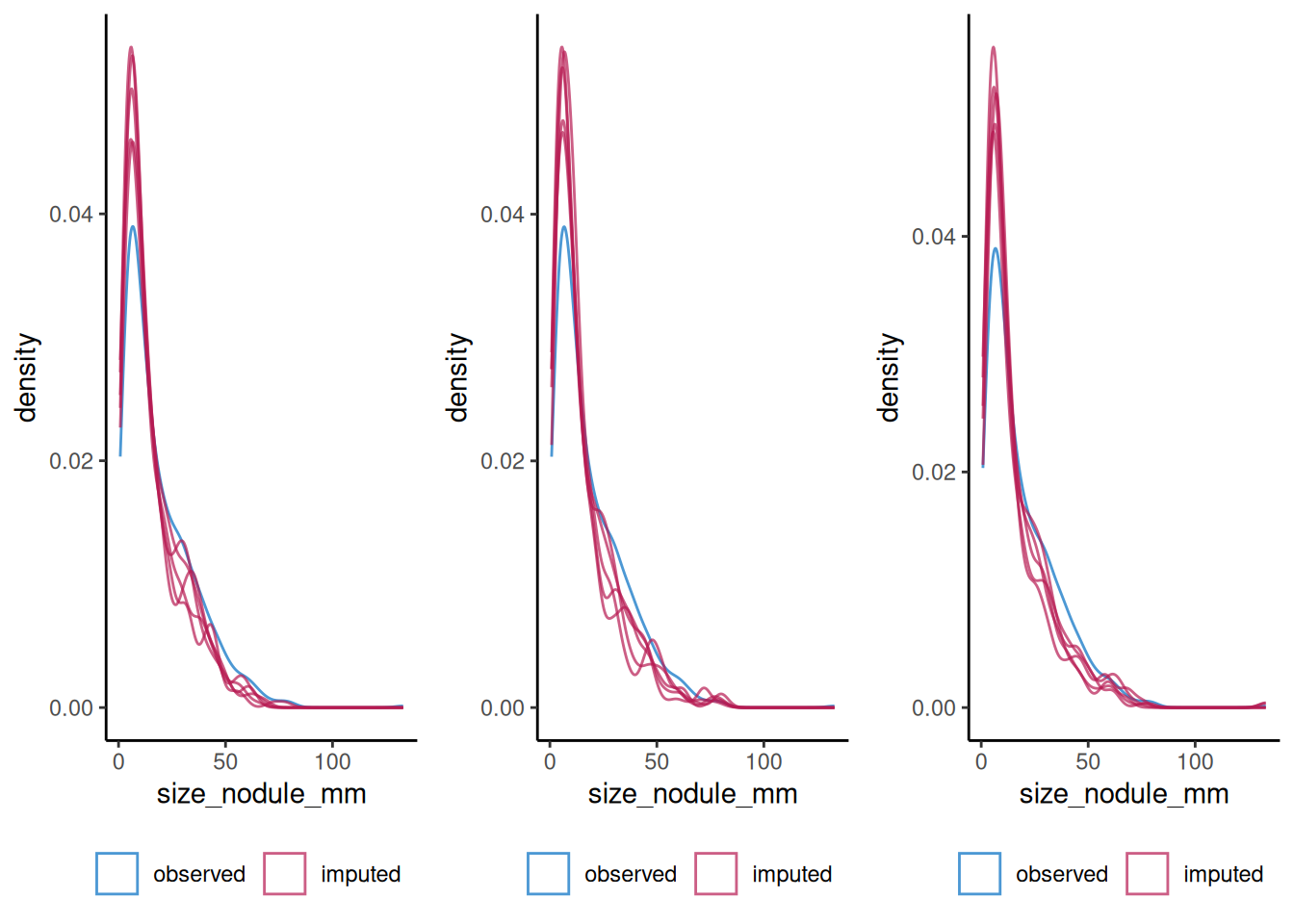
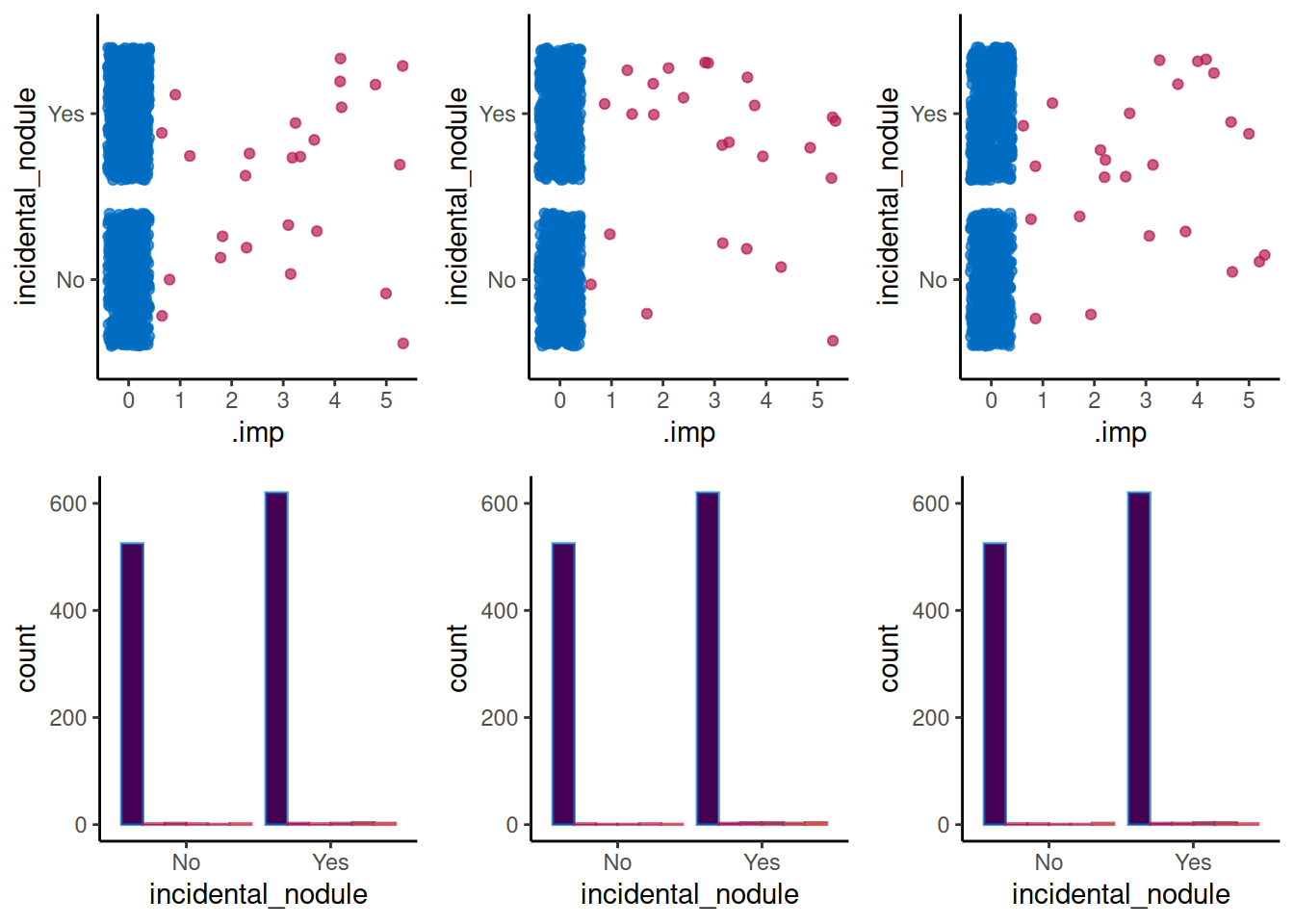
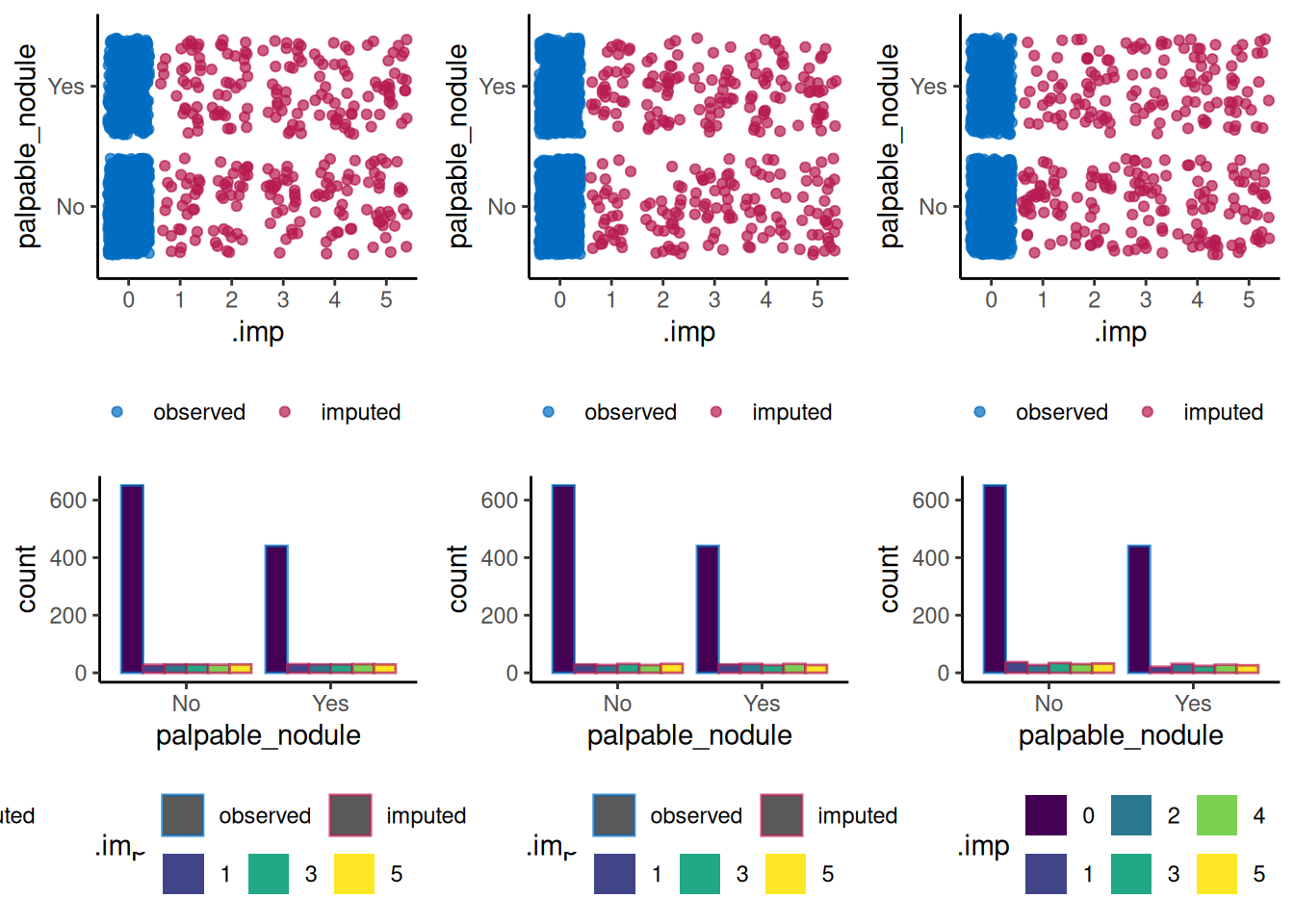
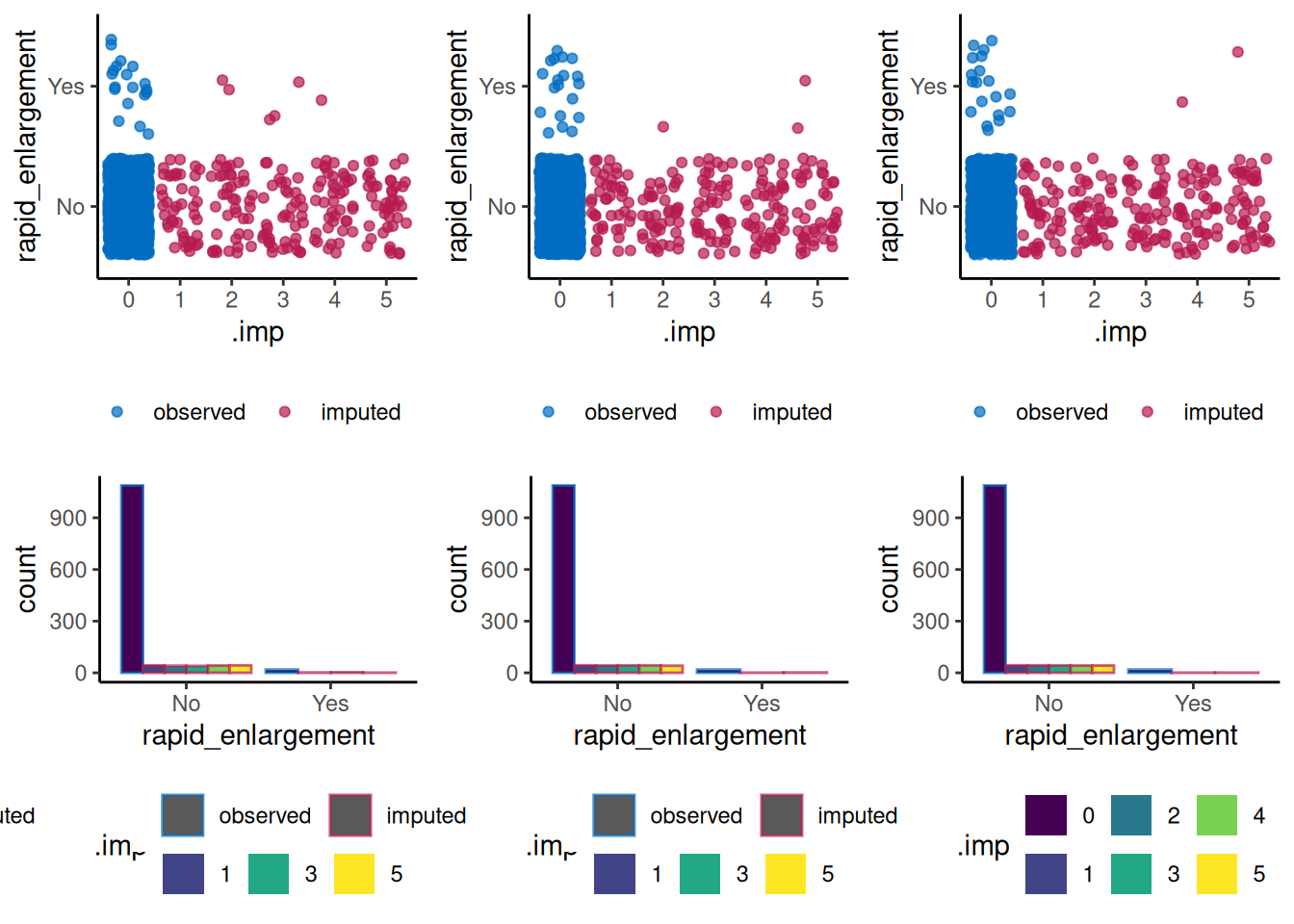
The MICE package@mice offers a number of different methods for imputing variables (see [documentation][mice_details]) we have investigated Predictive Mean Matching (PMM), Classification and Regression Trees (CART) and Random Forests (RF). Four rounds of imputation using each method were made.
A comparison of distributions/proportions before and after imputation are presented below to allow assessment of the utility of each method.
In [12]:
## Setup MICE mids for various methods###' Impute missing data and plot the results using the mice package.#'#' This is a wrapper around the functionality of the \href{https://amices.org/mice}{mice} and#' \href{https://amices.org/ggmice}{ggmice} packages for Multivariate Imputation by Chained Equations and visualisation#' of the resulting imputed datasets. Users should refer to the documentation for details of the options available.#'#' The wrapper uses \code{\link[mice]{futuremice}} to perform imputation in parallel using the same number of cores as#' the requested number of imputations. This speeds up the process but be wary if your computer has limited cores.#'#' @param df data.frame|tibble Data frame or tibble of original data.#' @param imputations int Number of imputations to perform.#' @param iterations int Number of iterations to perform for imputation.#' @param method str Method of imputation to use, see the Details section of \code{\link[mice]{mice}}.#' @param action str Action to take when running \code{\link[mice]{complete}}.#' @param include bool Logical of whether to include the original dataset in the output.#' @param seed int Seed for random number generation#'#'impute_data <-function(df = df_complete,outcome_var ="final_pathology",imputations =4,iterations =5,method ="pmm",action ="long",include =TRUE,continuous =c("albumin", "tsh_value", "lymphocytes", "monocyte", "size_nodule_mm"),categorical =c("ethnicity","incidental_nodule","palpable_nodule","rapid_enlargement","compressive_symptoms","hypertension","vocal_cord_paresis","graves_disease","hashimotos_thyroiditis","family_history_thyroid_cancer","exposure_radiation","bta_u_classification","solitary_nodule","cervical_lymphadenopathy","thy_classification"),seed =123) { results <-list()## Setup imputation results$mids <- df |> dplyr::select(-{{ outcome_var }}) |> mice::futuremice(m = imputations,method = method,n.core = imputations,iterations = iterations,parallelseed = seed)## Generate output dataset, results$imputed <- results$mids |> mice::complete(action ="long", include = include)## Convert the .imp variable which indicates the imputation set to factor with original dataset labelled as such results$imputed <- results$imputed |> dplyr::mutate(.imp =factor(.imp,levels =seq(0, imputations, 1),labels =c("Original", as.character(seq(1, imputations, 1)))))## We need to bind the outcome variable to each imputed dataset so they can be used in analyses outcome = df[[outcome_var]] n = imputationswhile(n >0) { outcome =append(outcome, df[[outcome_var]]) n <- n -1 } results$imputed <-cbind(results$imputed, outcome)colnames(results$imputed) <- stringr::str_replace(colnames(results$imputed), "outcome", outcome_var)## Plot traces of the imputation over iteration results$trace <- ggmice::plot_trace(results$mid)## Plot correlation between variables results$corr <- ggmice::plot_corr(df,label =TRUE,square =TRUE,rotate =TRUE,diagonal =FALSE)## Plot histograms of continuous variables results$histogram <-list()for (var in continuous) { results$histogram[[var]] <- ggmice::ggmice(results$mids, ggplot2::aes(x = .data[[var]],group = .imp)) + ggplot2::geom_density() }## Scatterplots and bar charts for categorical variables results$scatter <-list() results$bar_chart <-list()for (var in categorical) { results$scatter[[var]] <- ggmice::ggmice(results$mids, ggplot2::aes(x = .imp,y = .data[[var]])) + ggplot2::geom_jitter() results$bar_chart[[var]] <- ggmice::ggmice(results$mids, ggplot2::aes(x = .data[[var]],fill = .imp)) + ggplot2::geom_bar(position ="dodge") } results}## Impute using three different methods using the above impute_data() wrapperimputations =5iterations =5mice_pmm <-impute_data(method ="pmm",imputations = imputations,iterations = iterations,seed =684613)
Warning: Number of logged events: 25
Warning: Number of logged events: 25
Warning: Number of logged events: 25
Warning: Number of logged events: 24
Warning: Number of logged events: 24
TODO - Extract the legends from individual plots and add them to the end of each row, see the cowplot shared legends article for pointers on how to do this. Should ideally also get the fill colours to align with those used by ggmice.
TODO - And in light of having removed ?@tbl-data-completness in favour of the imputed datesets this too has been removed? (@ns-rse 2024-07-11). TODO - This table feels like duplication of ?@tbl-data-completeness, perhaps have just one? (@ns-rse 2024-07-11).
The predictor variables selected to predict final_pathology are shown in ?@tbl-predictors
Section that sets up the modelling
In [34]:
## Prefer tidymodel commands (although in most places we use the convention <pkg>::<function>())library(tidyverse)library(tidymodels)tidymodels::tidymodels_prefer()set.seed(5039378)## Use df_complete rather than df as this subset have data for all the variables of interest.## split <- rsample::initial_split(df_complete, prop = 0.75)## @ns-rse (2024-07-18) - Use an imputed dataset insteadsplit <- mice_rf$imputed |> dplyr::filter(.imp ==1) |> dplyr::select(-.imp, -.id) |> rsample::initial_split(prop =0.75)train <- rsample::training(split)test <- rsample::testing(split)
In [35]:
cv_folds <- rsample::vfold_cv(train, v =10, repeats =10)
In [36]:
cv_loo <- rsample::loo_cv(train)
In [37]:
## NB This is the key section where the variables that are to be used in the model are defined. A dependent variable## (the outcome of interest) is in this case the `final_pathology`, whether individuals have malignant or benign tumors,## this appears on the left-hand side of the equation (before the tilde `~`). On the right of the equation are the## predictor or dependant variables#### @ns-rse 2024-06-14 :## Because we have used dplyr::select() to choose _just_ the columns of interest we can use the '.'## notation to refer to "all other variables" as being predictors. This is useful as it saves duplication of writing## everything out which leaves scope for some being missed.thyroid_recipe <- recipes::recipe(final_pathology ~ ., data = train) |>## @ns-rse 2024-06-14 :## This step can be used to filter observations with missing data, see the manual pages for more details## https://recipes.tidymodels.org/reference/step_filter_missing.html recipes::step_filter_missing(recipes::all_predictors(), threshold =0) |>## @ns-rse 2024-06-14 :## We first normalise the data _before_ we generate dummies otherwise the dummies, which are numerical, get normalised## too recipes::step_normalize(recipes::all_numeric_predictors()) |> recipes::step_dummy(recipes::all_nominal_predictors())
The following section is output from a Tidymodel approach to logistic regression to try and work out why variables are not being included.
In [39]:
## define binary logistic regression modellogistic_model <-logistic_reg() |>set_engine("glm")## add the binary logistic regression model to the thyroid workflowlog_thyroid_workflow <- thyroid_workflow |>add_model(logistic_model)## fit the the workflow to the training datalog_thyroid_fit <-fit(log_thyroid_workflow, data = train)log_thyroid_fit## to inspect the fit objectstr(log_thyroid_fit)## use fitted model to make predictionlogistic_model_predictions <-predict(log_thyroid_fit, test) |>bind_cols(test)## examine the processing stepslog_thyroid_fit |>extract_recipe()## examine the modellog_thyroid_fit |>extract_fit_parsnip()## to check if the workflow has been trainedlog_thyroid_fit$trained## I can only see age and gender, unsure why the other variable not present.? excluded due to lack of data ?because they are simply not important ? issue with workflow set up
A total of 1150 patients had complete data for the selected predictor variables (see ?@tbl-predictors). Because of the volume of missing data which if a saturated model were used would include only ~350 people with complete data across all co-variates imputed datasets were analysed instead.
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: algorithm did not converge
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning in regularize.values(x, y, ties, missing(ties), na.rm = na.rm):
collapsing to unique 'x' values
Warning in regularize.values(x, y, ties, missing(ties), na.rm = na.rm):
collapsing to unique 'x' values
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Warning in regularize.values(x, y, ties, missing(ties), na.rm = na.rm):
collapsing to unique 'x' values
Characteristic
OR
1
95% CI
1
p-value
Age
0.99
0.97, 1.01
0.2
gender
1.19
0.58, 2.34
0.6
incidental_nodule
0.94
0.48, 1.84
0.9
TSH value
0.95
0.89, 1.00
0.091
Nodule size (mm)
1.04
1.02, 1.06
<0.001
solitary_nodule
1.49
0.77, 2.82
0.2
cervical_lymphadenopathy
6.61
1.45, 29.3
0.013
bta_u_classification
U1
—
—
U2
239,169
0.00, NA
>0.9
U3
3,105,400
0.00, NA
>0.9
U4
14,770,696
0.00, NA
>0.9
U5
39,781,959
0.00, NA
>0.9
thy_classification
Thy1
—
—
Thy1c
0.97
0.06, 7.66
>0.9
Thy2
0.25
0.06, 0.97
0.049
Thy2c
0.00
0.00, 1,045,453
>0.9
Thy3a
2.69
0.76, 9.91
0.13
Thy3f
2.45
0.92, 7.39
0.089
Thy4
8.34
2.18, 33.3
0.002
Thy5
11.1
3.47, 39.6
<0.001
1
OR = Odds Ratio, CI = Confidence Interval
3.2.2 LASSO
In [45]:
## Specify the LASSO model using parsnip, the key here is the use of the glmnet engine which is the R package for## fitting LASSO regression. Technically the package fits Elastic Net but with a mixture value of 1 it is equivalent to## a plain LASSO (mixture value of 0 is equivalent to Ridge Regression in an Elastic Net)tune_spec_lasso <- parsnip::logistic_reg(penalty = hardhat::tune(), mixture =1) |> parsnip::set_engine("glmnet")## Tune the LASSO parameters via cross-validationlasso_grid <- tune::tune_grid(object = workflows::add_model(thyroid_workflow, tune_spec_lasso),resamples = cv_folds,grid = dials::grid_regular(penalty(), levels =50))
In [46]:
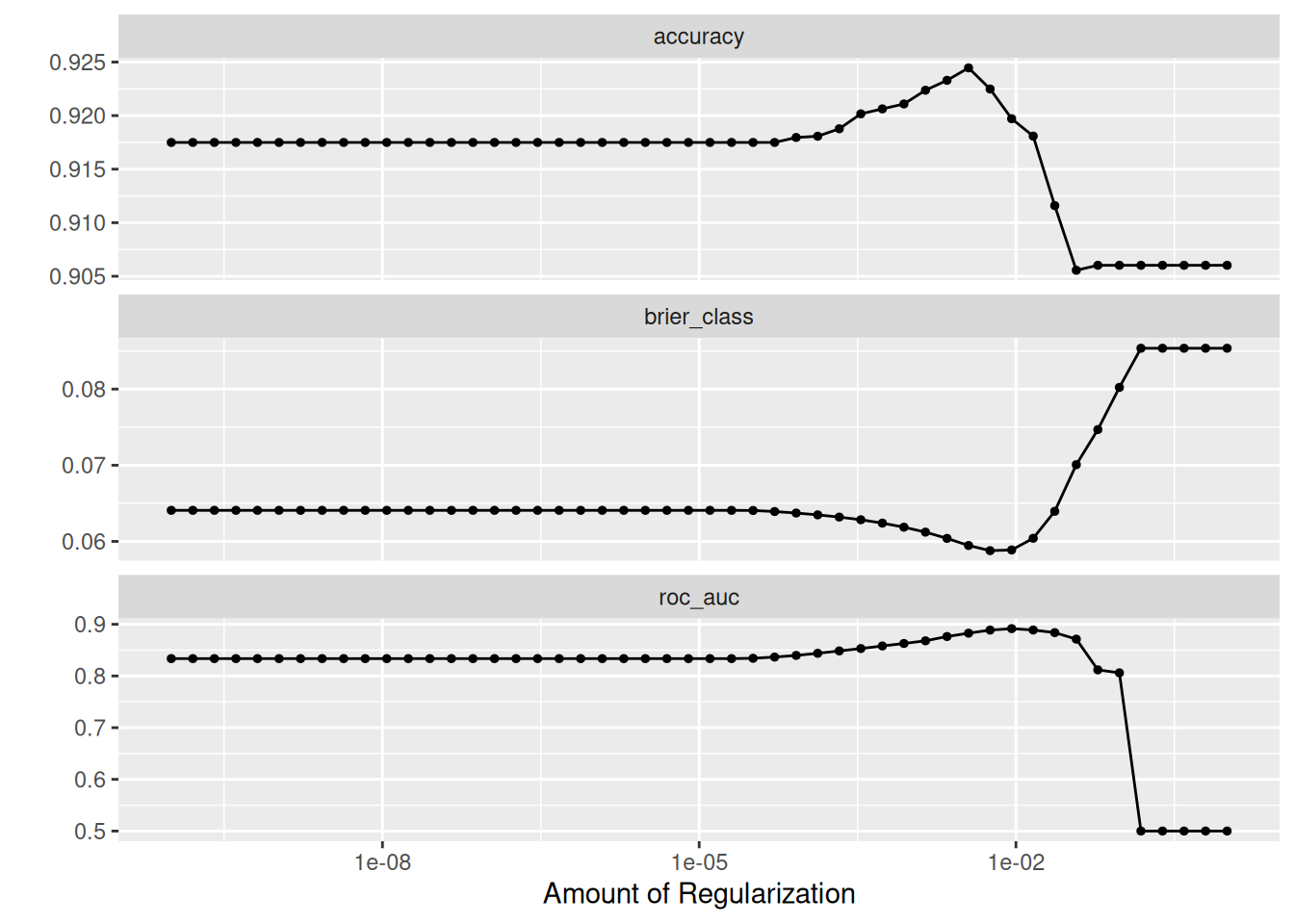
## Plot the tuning search results, see https://tune.tidymodels.org/reference/autoplot.tune_results.html#### This shows how the evaluation metrics change over time with each iteration of the Lasso (we know we are running a## LASSO because when we setup tune_spec_lasso the mixture = 1 when we define parsnip::logistic_reg()tune::autoplot(lasso_grid)
Figure 25: Importance of variables fitted using LASSO
NB - We may wish to inspect the coefficients at each step of tuning. A related example of how to do this can be found in the Tidymodels documentation under the Tuning a glmnet model. This would be desirable as it looks like only two features are selected as being important by this method and so rather than just accepting this I would want to investigate and see how the coefficients changed over iterations. Another useful resource is the glmnet documentation, although note that since we are using the Tidymodels framework the model fit is wrapped up inside (hence the above article on how to extract this information).
## Specify the Elastic Net model using parsnip, the key here is the use of the glmnet engine which is the R package for## fitting Elastic Net regression. Technically the package fits Elastic Net but with a mixture value of 1 it is equivalent to## a plain Elastic Net (mixture value of 0 is equivalent to Ridge Regression in an Elastic Net)tune_spec_elastic <- parsnip::logistic_reg(penalty = hardhat::tune(), mixture =0.5) |> parsnip::set_engine("glmnet")## Tune the Elastic Net parameters via cross-validationlasso_grid <- tune::tune_grid(object = workflows::add_model(thyroid_workflow, tune_spec_elastic),resamples = cv_folds,grid = dials::grid_regular(penalty(), levels =50))
In [52]:
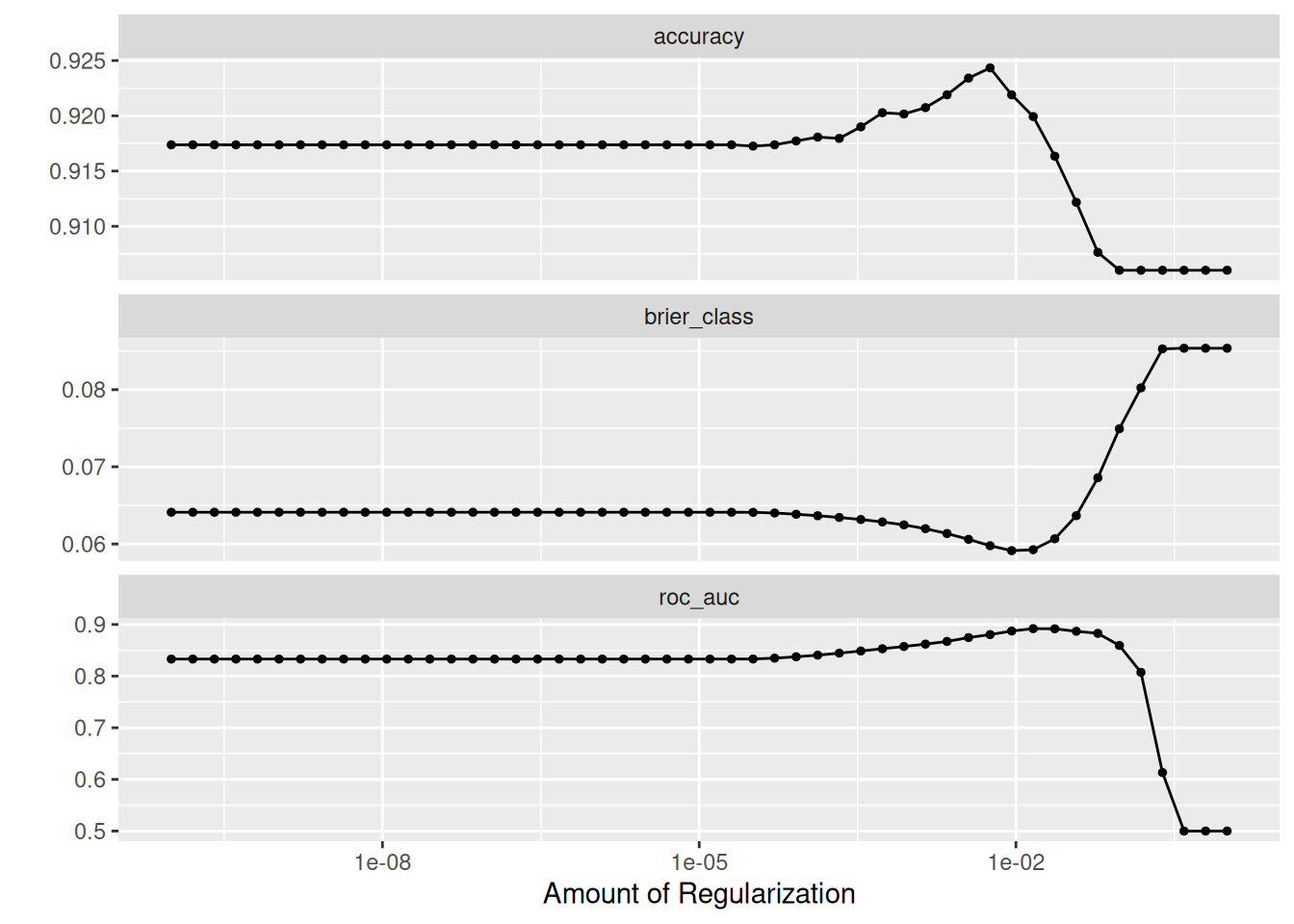
## Plot the tuning search results, see https://tune.tidymodels.org/reference/autoplot.tune_results.html#### This shows how the evaluation metrics change over time with each iteration of the Lasso (we know we are running a## Elastic Net because when we setup tune_spec_elastic the mixture = 1 when we define parsnip::logistic_reg()tune::autoplot(lasso_grid)
Figure 26: Autoplot of Elastic Net grid search
In [53]:
## K-fold best fit for Elastic Netlasso_kfold_roc_auc <- lasso_grid |> tune::select_best(metric ="roc_auc")
In [54]:
## Fit the final Elastic Net modelfinal_elastic_kfold <- tune::finalize_workflow( workflows::add_model(thyroid_workflow, tune_spec_elastic), lasso_kfold_roc_auc)
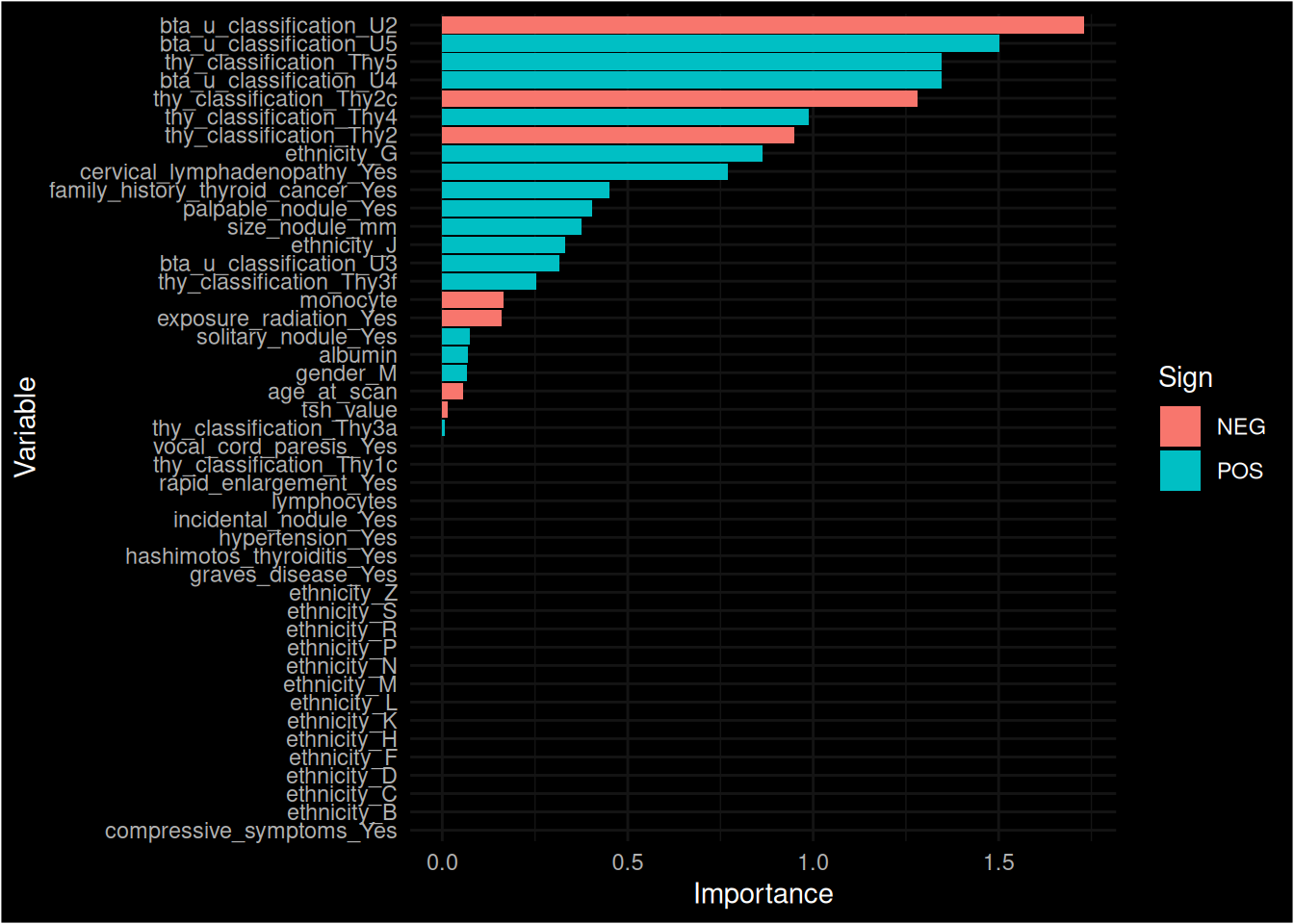
Inverted geom defaults of fill and color/colour.
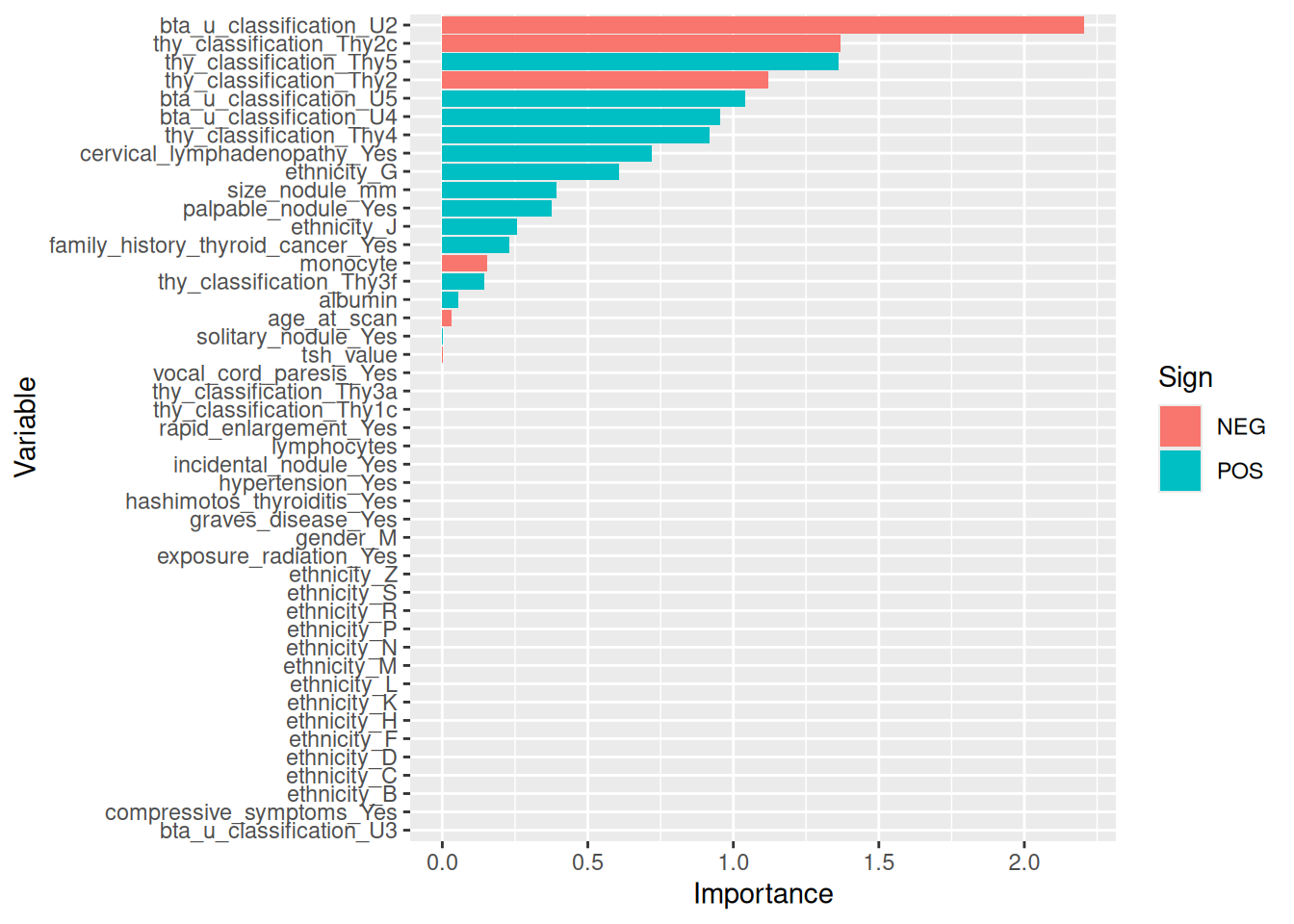
To change them back, use invert_geom_defaults().
Figure 27: Importance of variables fitted using Elastic Net
NB - We may wish to inspect the coefficients at each step of tuning. A related example of how to do this can be found in the Tidymodels documentation under the Tuning a glmnet model. This would be desirable as it looks like only two features are selected as being important by this method and so rather than just accepting this I would want to investigate and see how the coefficients changed over iterations. Another useful resource is the glmnet documentation, although note that since we are using the Tidymodels framework the model fit is wrapped up inside (hence the above article on how to extract this information).
## Specify the Random Forest modelrf_tune <- parsnip::rand_forest(mtry =tune(),trees =100,min_n =tune()) |>set_mode("classification") |>set_engine("ranger", importance ="impurity")## Tune the parameters via Cross-validationrf_grid <- tune::tune_grid(add_model(thyroid_workflow, rf_tune),resamples = cv_folds, ## cv_loo,grid =grid_regular(mtry(range =c(5, 10)), # smaller ranges will run quickermin_n(range =c(2, 25)),levels =3 ))## Get the best fitting model with the highest ROC AUCrf_highest_roc_auc <- rf_grid |>select_best()
Warning in select_best(rf_grid): No value of `metric` was given; "roc_auc" will
be used.
## Specify the Gradient boosting modelmodel_xgboost <- parsnip::boost_tree(mode ="classification",trees =100,min_n =tune(),tree_depth =tune(),learn_rate =tune(),loss_reduction =tune()) |>set_engine("xgboost", objective ="binary:logistic")## Specify the models tuning parameters using the `dials` package along (https://dials.tidymodels.org/) with the grid## space. This helps identify the hyperparameters with the lowest prediction error.xgboost_params <- dials::parameters(min_n(),tree_depth(),learn_rate(),loss_reduction())xgboost_grid <- dials::grid_max_entropy( xgboost_params,size =10)## Tune the model via cross-validationxgboost_tuned <- tune::tune_grid(workflows::add_model(thyroid_workflow, spec = model_xgboost),resamples = cv_folds,grid = xgboost_grid,metrics = yardstick::metric_set(roc_auc, accuracy, ppv),control = tune::control_grid(verbose =FALSE))
In [61]:
## We get the best final fit from the Gradient Boosting model.xgboost_highest_roc_auc <- xgboost_tuned |> tune::select_best()
Warning in tune::select_best(xgboost_tuned): No value of `metric` was given;
"roc_auc" will be used.
Length Class Mode
pre 3 stage_pre list
fit 2 stage_fit list
post 1 stage_post list
trained 1 -none- logical
## it is unclear from the output what predictors were significant, so i need to examin the model to see what predictors were usedpreprocessor <- final_fit |>extract_preprocessor()## view the predictors evaluatedsummary(preprocessor)
# A tibble: 23 × 4
variable type role source
<chr> <list> <chr> <chr>
1 age_at_scan <chr [2]> predictor original
2 gender <chr [3]> predictor original
3 ethnicity <chr [3]> predictor original
4 incidental_nodule <chr [3]> predictor original
5 palpable_nodule <chr [3]> predictor original
6 rapid_enlargement <chr [3]> predictor original
7 compressive_symptoms <chr [3]> predictor original
8 hypertension <chr [3]> predictor original
9 vocal_cord_paresis <chr [3]> predictor original
10 graves_disease <chr [3]> predictor original
# ℹ 13 more rows
## above showed the variables used## the next line shows the extracts the fitted model from the work flowmodel_xgboost <-extract_fit_parsnip(final_fit)$fitsummary(model_xgboost)
Length Class Mode
handle 1 xgb.Booster.handle externalptr
raw 95013 -none- raw
niter 1 -none- numeric
evaluation_log 2 data.table list
call 8 -none- call
params 10 -none- list
callbacks 1 -none- list
feature_names 45 -none- character
nfeatures 1 -none- numeric
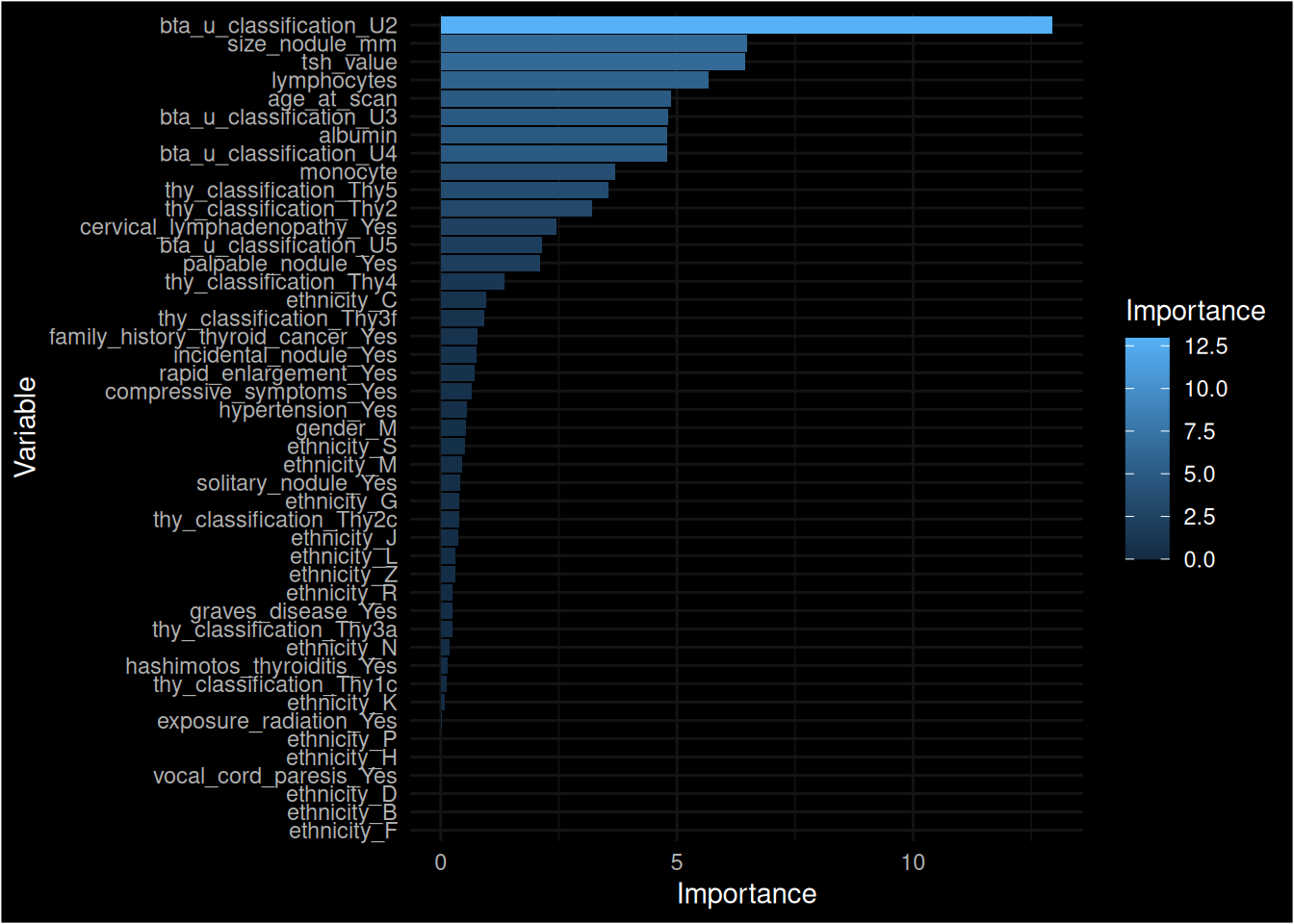
## the next code evaluate the important variablesimportance_xgboost <- xgboost::xgb.importance(model = model_xgboost)print(importance_xgboost)
## the print shows age and gender as important## to make a prediction on the train setxgboost_predictions <-predict(final_fit, test, type ="prob") |>bind_cols(predict(final_fit, test)) |>bind_cols(test)colnames(xgboost_predictions)
## analyse model performance using roc curves, need to figure out what "truth" and estimate refers to here, as final_pathology and .pred_Cancer do not run## roc_auc <- xgboost_predictions |>## roc_auc(truth = , estimate = )
In [62]:
save(xgboost_tuned, xgboost_grid, final_xgboost, importance_xgboost, model_xgboost, ## xgboost_highest_roc_auc,file ="data/r/xgboost.RData")``#### SVM<!-- {{< include sections/_svm.qmd >}} -->#### ExplainabilityWhich factors are important to classification can be assessed not just by the "importance" but by methods know as[LIME](https://search.r-project.org/CRAN/refmans/lime/html/lime-package.html) (Local Interpretable Model-AgnosticExplanations) @ribeiro2016 and [Shapleyvalues](https://shap.readthedocs.io/en/latest/example_notebooks/overviews/An%20introduction%20to%20explainable%20AI%20with%20Shapley%20values.html)@lundberg2017#### ComparisionComparing the sensitivity of the different models goes here.+ Table of sensitivity/specificity/other metrics.+ ROC curves## ConclusionThe take-away message is....these things are hard!## Appendix### Data Dictionary
In [63]:
In [64]:
var_labels |>as.data.frame() |>kable(col.names =c("Description"),caption="Description of variables in the Sheffield Thyroid dataset.")
Table 3: Description of variables in the Sheffield Thyroid dataset.
Description
age_at_scan
Age
albumin
Albumin
bta_u_classification
BTA U
cervical_lymphadenopathy
Cervical Lymphadenopathy
compressive_symptoms
Compressive symptoms
consistency_nodule
Nodule consistency
eligibility
Eligibility
ethinicity
Ethinicity
ethnicity
Ethnicity
exposure_radiation
Exposure to radiation
family_history_thyroid_cancer
Family history of thyroid cancer
final_pathology
Final diagnosis
fna_done
FNA done
gender
Gender
graves_disease
Graves’ disease
hashimotos_thyroiditis
Hashimoto’s disease
hypertension
Hypertension
incidental_nodule
Incidental nodule
lymphocytes
Lymphocytes
monocyte
Monocytes
palpable_nodule
Palpable nodule
rapid_enlargement
Rapid enlargement
repeat_bta_u_classification
Repeat BTA U
repeat_fna_done
Repeat FNA
repeat_thy_classification
Repeat Thy class
repeat_ultrasound
Repeat ultrasound
size_nodule_mm
Nodule size (mm)
solitary_nodule
Solitary nodule
study_id
Study ID
thy_classification
Thy classification
thyroid_histology_diagnosis
Histology
thyroid_surgery
Thyroid surgery
tsh_value
TSH value
vocal_cord_paresis
Vocal cord paresis
Buuren, Stef van, and Karin Groothuis-Oudshoorn. 2011. “mice: Multivariate Imputation by Chained Equations in R.”J. Stat. Soft. 45 (December): 1–67. https://doi.org/10.18637/jss.v045.i03.
Efron, Bradley, and Trevor Hastie. 2016. Computer Age Statistical Inference: Algorithms, Evidence, and Data Science. Cambridge Core. Cambridge, England, UK: Cambridge University Press. https://doi.org/10.1017/CBO9781316576533.
Kuhn, Max, and Hadley Wickham. 2020. Tidymodels: A Collection of Packages for Modeling and Machine Learning Using Tidyverse Principles.https://www.tidymodels.org.
R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.
“Regression Shrinkage and Selection via the Lasso.” 1996. Journal of the Royal Statistical Society. Series B (Methodological). https://www.jstor.org/stable/2346178.
Steyerberg, Ewout W., Marinus J. C. Eijkemans, Frank E. Harrell, and Dik. 2001. “Prognostic Modeling with Logistic Regression Analysis.”Medical Decision Making 21 (1): 45–56. https://doi.org/10.1177/0272989x0102100106.
Thompson, Bruce. 1995. “Stepwise Regression and Stepwise Discriminant Analysis Need Not Apply Here: A Guidelines Editorial.”Educational and Psychological Measurement 55 (4): 525–34. https://doi.org/10.1177/0013164495055004001.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.”Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Zou, Hui, and Trevor Hastie. 2005. “Regularization and Variable Selection Via the Elastic Net.”J. R. Stat. Soc. Ser. B. Stat. Methodol. 67 (2): 301–20. https://doi.org/10.1111/j.1467-9868.2005.00503.x.